




2. 400038 重庆,陆军军医大学(第三军医大学)第一附属医院信息科;
3. 114000 辽宁 鞍山,中国人民解放军第65547部队卫生连;
4. 400042 重庆,陆军特色医学中心医学:放射科;
5. 400042 重庆,陆军特色医学中心医学战创伤医学中心,创伤与化学中毒全国重点室验室
2. Department of Information, First Affiliated Hospital, Army Medical University (Third Military Medical University), Chongqing, 400038;
3. Health Company of Troop 65547 of PLA, Anshan, Liaoning Province, 114000, China;
4. Department of Radiology, Army Medical Center of PLA, Chongqing, 400042;
5. Division of Trauma and War Injury, State Key Laboratory of Trauma and Chemical Poisoning, Army Medical Center of PLA, Chongqing, 400042
股骨骨折好发于老年人群,被称为“人生最后一次骨折”,发病率呈逐年上升趋势[1]。股骨骨折包括股骨头骨折、股骨颈骨折、股骨转子间骨折、股骨干骨折以及远端股骨骨折,其中股骨转子间骨折发生率最高(占50%),且患者1年死亡率高达17.47%[2],不及时正确治疗可能会影响老年人的生活质量甚至威胁生命。在转子间骨折诊断过程中,X线平片检查具有可靠性高、成本低廉、易于实施、安全性高等多种优点,因此是首选的检查方式[3]。临床转子间骨折分型指南参照2018版Arbeitsgemeinschaft für Osteosynthese-fragen/Orthopaedic Trauma Association(AO/OTA)执行,将转子间骨折分为A1.1、A1.2、A1.3、A2.2、A2.3、A3.1、A3.2、A3.3亚组[4]。亚组对应不同手术方式以及术中风险程度。
随着医学影像技术的快速发展,传统的骨折诊断方法正朝着自动化、智能化的方向发展。目前,深度学习模型已被广泛应用于骨折识别领域,与传统方法比较其诊断效能更优[5]。在这些深度学习模型中,多数使用卷积神经网络(convolutional neural network,CNN)或注意力机制网络(Transformer)进行特征提取和分类任务[6-7]。YOLO系列网络是目前学术及工程中运用最广的目标识别网络之一,主要包括YOLOv4、YOLOv5、YOLOX[8-10]等。注意力机制网络中的Swin Transformer[11]网络在分类、目标识别以及分割任务上均取得了非常好的效果[12-14],因此采用Swin Transformer替代YOLOX主干网络可能会得到更好的识别效果。目前大量的医学影像采用深度学习的方法进行智能化处理,但是输入图像的分辨率往往选择默认大小[15-18],是否能够获得较优识别效果无法确定,或者需要反复尝试,造成了严重的资源和时间浪费。因此亟须系统性地探究图像输入分辨率大小对YOLO系列目标识别网络识别效果的影响,本研究对进行类似的下游识别任务具有明确的借鉴和指导意义。
1 材料与方法 1.1 研究对象本研究通过陆军特色医学中心医学伦理委员会的审查与批准[医研伦审(2023)第148号]。采集陆军特色医学中心2017-2022年间确诊为股骨转子间骨折患者的X线影像学资料。纳入标准:①符合AO/OTA(2018)版分型标准的转子间骨折患者;②年龄≥18周岁;③股骨正位图像。排除标准:①术后检查的患者;②摆位不正和股骨包含不全的图像;③质量不佳的图像;④股骨处有异物遮挡的图像。
最终按照纳入标准和排除标准执行后符合要求的转子间骨折患者共计426例,图像847幅。X线图像从本中心以DICOM格式导出,首先需要经RadiAnt DICOM Viewer软件将DICOM格式转换为JPG格式,并在格式转化时采用匿名化处理,隐去所有患者身份信息,以此实现数据脱敏,保护患者隐私。格式转换后的图像由2名创伤外科工作年限>10年的专家利用LabelImg软件进行标注,1名工作年限>10年的专家负责审核。深度学习中样本量的估算主要采用经验法,结合医学图像数量少、获取及标注难度大的特点,在采用迁移学习训练方法时要求每一分类图像数量应不少于100例。结合转子间骨折各亚组数据分布特点及实际临床发病率,本研究剔除了发病率极低且多采用保守治疗的A1.1亚组,并将手术处理方面几乎无差异,且术中风险等级均较高的A3.1、A3.2与A3.3分型统一视为A3亚组不再细化。最终,本研究将转子间骨折分为A1.2、A1.3、A2.2、A2.3、A3 5个亚组,数据按8 ∶1 ∶1的比例划分训练集、验证集和测试集,并在所有试验中保持不变。其中训练集用于网络训练,验证集用于训练过程中的验证,网络根据验证的结果不断调整学习率等参数重新训练,测试集用于模型训练完毕后的性能测试阶段。各亚组的数据量如表 1所示。由表 1可见各亚组的训练集数量均高于100,样本量符合要求。
| 分型 | A1.2 | A1.3 | A2.2 | A2.3 | A3 | 合计 |
| 训练集 | 140 | 130 | 159 | 125 | 124 | 678 |
| 验证集 | 18 | 16 | 20 | 15 | 15 | 84 |
| 测试集 | 17 | 16 | 20 | 16 | 16 | 85 |
| 合计 | 175 | 162 | 199 | 156 | 155 | 847 |
1.2 试验设计 1.2.1 试验环境
本研究基于本地服务器完成,操作系统为Ubuntu 18.04,GPU为双RTX3090,编译平台为PyCharm Community Edition 2021.2.1,编译语言为python3.7,编译环境为pytorch1.7和torchversion0.8.0。试验中的超参数设置如下:epoch为385,批次大小为8,学习率为0.001。优化器使用Adam优化器,损失函数使用交叉熵函数。数据增强选择mosiac增强和mixup混合增强模式,模型保存策略是每100个epoch保存1次,每10个epoch进行1次验证,并迭代保存准确率最高的模型,同时保存最后1个epoch的模型。
1.2.2 试验流程训练参数和超参数保持不变的前提下,改变图像输入分辨率分别为深度学习任务中常用的224×224、320×320、416×416、480×480、576×576、640×640、736×736、800×800,依次对YOLOX-Swin-Transformer、YOLOX、YOLOv5、YOLOv4目标识别网络的base网络进行从头训练和迁移学习训练,迁移学习的权重采用VOC 2012数据集训练所得预训练权重,记录训练时间。采用测试集对所得模型进行测试,并记录模型的评价指标。
1.2.3 评价指标精确率(precision)、召回率(recall)、召回率的调合均值(F1_score)、平均精度(average precision,AP)和均值平均精度(mean average precision,mAP)被用作评估分类网络效果的方法。相应的公式如下:
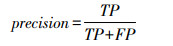
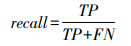
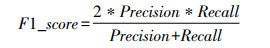
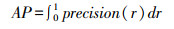
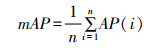
其中,TP、TN、FP、FN分别为真正例、真反例、假正例、假反例的数量。
AP值是由改变阈值形成的precision-recall(P-R) 曲线下的面积,其以recall值作为横轴,precision值作为纵轴进行绘制,每种类型的AP值取算术平均值来获得mAP值。AP值能够直观地反映每种分类的性能,而mAP值则能够直观地反映模型的整体分类性能。
1.3 统计学分析数据采用SPSS20.0统计软件进行分析。对各网络训练耗时分别进行线性拟合,给出拟合公式,对所有网络在不同输入分辨率条件下训练所得mAP值求平均后,采用非线性回归分析中的曲线拟合功能对各输入分辨率下所有网络mAP的均值进行拟合,给出拟合公式,拟合优度R2>0.5则认为拟合程度较好,P < 0.05认为差异有统计学意义。
强制分布法是指根据实际情况事先确定好评级的分布比例,再根据数据从高到低排序将结果强制分类到事先划分好的比例中,从而达到区分优、良、差的目的[19]。本研究借鉴此方法,综合考虑AP、F1_score、presicion、recall评价指标,将不同输入分辨率下各亚组的评价指标从高到低排序,前25%的数据评级定义为优,若数值相同则视为同一评级,50%的数据定义为良,余下25%的数据定义为差。
采用频数统计功能对各输入分辨率下评价指标为优的频数进行统计,根据公式:频率=频数/总数×100%计算频率,其中总数为评级为优的总体数量。频率之和最高的相邻的3个输入分辨率即视为网络最佳识别效果出现概率最高的输入分辨率范围。
2 结果 2.1 YOLO系列网络在不同输入分辨率条件下训练耗时的线性回归分析对各网络不同图像输入分辨率条件下训练耗时做散点图并绘制拟合曲线见图 1:输入图像分辨率与YOLO系列网络的训练耗时均呈现良好的线性关系,各拟合曲线均有R2>0.5,P < 0.05,说明线性回归拟合效果有统计学意义。从图中趋势可以看出图像输入分辨率越高,训练耗时越长。尤其是YOLOX-Swin-Transformer网络,当采用从头训练方法输入在224×224时,训练耗时4.03 h,当输入增加至800×800时,训练时间增加至8.11 h。当相同网络采用迁移学习方法时,训练时间均有所减少,这一特点在YOLOX网络上格外明显。

|
| transfor:迁移学习方法;R2:拟合优度 图 1 采用迁移学习和从头训练方法的YOLO系列网络在不同输入分辨率条件下的训练耗时 |
2.2 YOLO系列网络转子间骨折亚组识别mAP的非线性回归分析
YOLOX-Swin-Transformer、YOLOX、YOLOv5、YOLOv4网络在不同输入分辨率下的mAP值以及所有网络mAP均值的拟合结果见图 2。由SPSS统计分析软件曲线拟合结果R2=0.843,P=0.011可知曲线拟合优度较好,回归分析有统计学意义。从图 2中可以看出,当采用从头训练方法时,YOLOX-Swin-Transformer网络在输入分辨率为576×576时取得最大mAP值为80.07%。当采用迁移学习方法时,YOLOX网络在输入为640×640时取得最大mAP值为86.79%。从拟合曲线的走势上看,输入分辨率在576×576上各网络mAP均值取得峰值。

|
| transfor:迁移学习方法;R2为拟合优度;mAP为平均精准度 图 2 YOLO系列网络在不同输入分辨率条件下的mAP值以及mAP均值的拟合曲线 |
2.3 评价指标评级为优的频数分析
采用SPSS统计分析软件对各输入分辨率下AP、F1_score、recall、precision评价指标评级为优的进行频数统计,并通过频率计算公式计算后所得结果见图 3:当图像输入分辨率取576×576、480×480、640×640时,评价指标为优的频率取得最高的3个值分别为15.02%、14.29%、13.55%,此区间出现评价指标最优频率占整体的42.86%。

|
| 图 3 YOLO系列网络各输入分辨率下转子间骨折亚组识别评价指标评级为优的频率分布 |
2.4 不同方法对网络识别效果的提升
为探究改变分辨率和采用迁移学习方法对网络分型识别效果的提升情况,对采用不同方法mAP的最大值与最小值进行计算最值差,结果见表 2:仅改变输入分辨可以使YOLO系列网络转子间骨折分型识别mAP值获得平均6.83%的提升,仅采用迁移学习方法可以获得4.16%的提升,而采用迁移学习方法同时改变输入分辨率可以平均9.04%的提升。充分说明改变输入分辨率和采用迁移学习方法的单独或混合使用均可以有效提高各网络目标检测效果,且混合使用效果提升最为显著。
| 方法 | YOLOX-Swin-Transformer | YOLOX | YOLOv5 | YOLOv4 | 平均 |
| 改变输入分辨率 | 4.30 | 5.24 | 10.99 | 6.79 | 6.83 |
| 迁移学习 | 2.68 | 6.06 | 5.11 | 2.79 | 4.16 |
| 迁移学习+改变输入分辨率 | 7.09 | 6.54 | 12.94 | 9.60 | 9.04 |
3 讨论 3.1 YOLO系列网络识别效果取得最优的输入分辨率范围
本研究探究了采用从头学习和迁移学习方法的YOLOX-Swin-Transformer、YOLOX、YOLOv5、YOLOv4目标识别网络在图像输入分辨率分别为224×224、320×320、416×416、480×480、576×576、640×640、736×736、800×800的条件下对转子间骨折AO/OTA(2018)亚组分型效果的影响。结果表明,图像输入分辨率控制在480×480、576×576、640×640范围内时,获得最优网络识别效果的概率最高。采用从头训练方法时,YOLOX-Swin-Transformer网络在576×576处取得了最高mAP值,当采用迁移学习训练方法时,YOLOX网络在640×640处取得了最高mAP值。模型训练耗时与输入分辨率呈现良好的正相关,说明图像输入分辨率的增加会显著增加资源消耗,当图像输入分辨率高于640×640后训练耗时增加的同时识别效果也会降低,迁移学习能够明显缩短训练时间,节约训练资源并且有助于准确率的提升。
3.2 特殊情况的探讨YOLOv5网络在从头训练和迁移学习中识别效果均为最差,究其原因主要是发生了欠拟合。YOLOv5网络与YOLOv4网络同年发布,但并非继承了YOLOv4的框架,而是基于YOLOv3[20]框架的改进,其模型更小,检测速度更快。要达到更好的效果必须有更多的训练数据,因此对于数据量相对较少的下游任务出现了严重的欠拟合。尤其是采用从头训练方法时,不同图像输入分辨率下A2.2亚组和A2.3亚组分型AP值最低仅为35%与5.84%。当采用迁移学习训练方法时,虽然识别效果得到了改善,但是仍不如其他网络。YOLOv5网络的优势是训练耗时最少,但是代价是识别效果的牺牲。因此对于数据量相对较少且对识别精度要求较高的医用图像识别任务,应减少使用YOLOv5网络。
YOLOX-Swin-Transformer网络在采用迁移学习训练方法时与其他网络呈现出的规律有所不同,其在224×224时取得了最优识别效果(mAP=83.5%)。究其原因主要是A3亚组在输入分辨率为224×224时达到了100%,但A2.2亚组AP值仅为57.41%。相较于分辨率为480×480时(mAP=83.1%),A3亚组AP值(99.38%),A2.2亚组AP值(65.28%)而言,后者虽然整体识别效果不如前者,但后者各亚组识别效果更加均衡。因此,从各亚组数据均衡程度来看,该网络仍然可以认为在480×480、576×576、640×640范围内取得了较优的识别效果。
3.3 相关研究对比REDMON等[20]对YOLOv3网络3种图像输入分辨率(320×320、416×416、608×608)进行训练所得mAP由51.5%提高至57.9%,单张图像预测时间由22 s上升至51 s,结果表明提高图像输入分辨率可以提高检测精度,但也会增加计算量和内存消耗。HUANG等[21]利用300×300和600×600两种分辨率对Faster RCNN、R-FCN、SSD网络进行效果对比,结果表明当输入分辨率从300×300增加至600×600时,精度平均提高15.88%,同时推理时间平均增加了27.4%。这与本研究结果即网络识别效果在480×480、576×576、640×640范围内取得最优的概率最高的结论部分一致,不同的是本研究结果显示并不是图像输入分辨率越高网络识别效果越好,而是在一定范围内随着图像输入分辨率的增高而增高,当图像输入分辨率高于640×640时,几乎所有的网络识别效果均开始下滑。原因是只增加了输入图像的分辨率,未对YOLO系列网络的结构进行任何改变,因此感受野的大小是固定不变的。感受野是指卷积神经网络中每个神经元接收信息的区域大小,决定了神经元能够感知的局部特征区域[22]。过大的图像分辨率导致了特征层的尺寸同样过大,感受野在图像中的占比就会下降,这会导致网络在提取特征时过于依赖局部信息,从而无法充分利用全局特征,进而导致检测精准率的下降。过多的局部特征也导致了计算量的增加和过拟合风险的加大,这也是训练耗时不断增加的主要原因。同时也验证了TAN等[22]在Efficientnetv2网络中得出的输入图像尺寸越大越容易发生过拟合的结论。因此若对超高分辨率的图像进行目标检测任务时,需要修改原有网络结构,采用合适的感受野匹配特征层的大小,才能够取得更优的识别效果。
3.4 研究缺陷与总结本研究的不足之处在于未对224×224到800×800分辨率范围内所有32的倍数的分辨率进行试验,对最优点有可能发生遗漏。在接下来的研究中,本研究将会探究如何调整网络结构来适应更高的分辨率,使高分辨率医学图像真正发挥细节上的优势。
本研究旨在探究高分辨率医学图像输入分辨率对YOLO系列网络在转子间骨折AO/OTA(2018)分型任务上识别效果的影响。通过对比不同图像输入分辨率下的模型性能发现并非图像输入分辨率越高,模型的识别效果越高,而是最优识别效果在480×480、576×576、640×640范围内出现概率最大,同时过高的分辨率会导致训练成本的增加。本研究为具有高分辨的医学影像领域的自动化诊断任务提供了借鉴,也显示了图像输入分辨率与深度学习模型性能之间的具体关系。为医学影像领域的研究提供了参照,也为后续类似研究提供了重要的参考。
| [1] |
牛国庆, 吴峰, 彭智浩, 等. 股骨粗隆间骨折PFNA内固定失效手术因素分析[J]. 中国临床解剖学杂志, 2020, 38(6): 728-734. NIU G Q, WU F, PENG Z H, et al. Analysis of surgical factors of failure of PFNA after intertrochanteric fracture[J]. Chin J Clin Anat, 2020, 38(6): 728-734. |
| [2] |
CUI Z Y, FENG H, MENG X Y, et al. Age-specific 1-year mortality rates after hip fracture based on the populations in mainland China between the years 2000 and 2018: a systematic analysis[J]. Arch Osteoporos, 2019, 14(1): 1-10. |
| [3] |
MEINBERG E G, AGEL J, ROBERTS C S, et al. Fracture and dislocation classification compendium-2018[J]. J Orthop Trauma, 2018, 32(Suppl 1): S1-S170. |
| [4] |
张世民, 余斌. AO/OTA-2018版股骨转子间骨折分类的解读与讨论[J]. 中华创伤骨科杂志, 2018, 20(7): 583-587. ZHANG S M, YU B. Interpretation of and discussion on AO/OTA-2018 Fracture Classification of Femoral Per/Inter-trochanteric Fractures[J]. Chin J Orthop Trauma, 2018, 20(7): 583-587. |
| [5] |
伍亚舟, 陈锡程, 易东. 人工智能在临床领域的研究进展及前景展望[J]. 陆军军医大学学报, 2022(1): 89-102. WU Y Z, CHEN X C, YI D. Advances and perspective of artificial intelligence in clinical area[J]. J Army Med Univ, 2022(1): 89-102. |
| [6] |
LECUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition[J]. Proc IEEE, 1998, 86(11): 2278-2324. |
| [7] |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all You need[EB/OL]. 2017: arXiv: 1706.03762. https://arxiv.org/abs/1706.03762.
|
| [8] |
BOCHKOVSKIY A, WANG C Y, LIAO H Y M. YOLOv4: optimal speed and accuracy of object detection[EB/OL]. 2020: arXiv: 2004.10934. https://arxiv.org/abs/2004.10934.
|
| [9] |
REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[EB/OL]. 2015: arXiv: 1506.02640. https://arxiv.org/abs/1506.02640.
|
| [10] |
GE Z, LIU S, WANG F, et al. YOLOX: exceeding YOLO series in 2021[EB/OL]. 2021: arXiv: 2107.08430. https://arxiv.org/abs/2107.08430.
|
| [11] |
LIU Z, LIN Y, CAO Y, et al. Swin transformer: hierarchical vision transformer using shifted windows[EB/OL]. 2021: arXiv: 2103.14030. https://arxiv.org/abs/2103.14030.
|
| [12] |
刘学思, 聂瑞, 张和华, 等. 基于Swin Transformer网络的肺结核影像自动分类效果评价[J]. 中国医疗设备, 2022, 37(8): 25-31, 65. LIU X S, NIE R, ZHANG H H, et al. Effect evaluation of automatic classification of pulmonary tuberculosis images based on swin transformer network[J]. China Med Devices, 2022, 37(8): 25-31, 65. |
| [13] |
许杉杉, 呼延若曦, 吴哲, 等. 基于深度学习的MRI图像下前列腺癌T分期诊断研究[J]. 陆军军医大学学报, 2023, 45(11): 1229-1236. XU S S, HUYAN R X, WU Z, et al. Prostate cancer T-stage intelligent diagnosis based on MRI images and deep learning[J]. J Army Med Univ, 2023, 45(11): 1229-1236. |
| [14] |
LIAO Z H, FAN N, XU K. Swin transformer assisted prior attention network for medical image segmentation[J]. Appl Sci, 2022, 12(9): 4735. |
| [15] |
吴育鑫, 薛蕴菁, 段青, 等. 基于深度学习的计算机辅助诊断系统检出DR胸部正位片中的骨折[J]. 中国介入影像与治疗学, 2020, 17(11): 675-678. WU Y X, XUE Y J, DUAN Q, et al. Deep-learning based computer aided diagnosis system in detecting fractures on anteroposterior chest DR films[J]. Chin J Interv Imaging Ther, 2020, 17(11): 675-678. |
| [16] |
LI W, XIAO Z L, LIU J, et al. Deep learning-assisted knee osteoarthritis automatic grading on plain radiographs: the value of multiview X-ray images and prior knowledge[J]. Quant Imaging Med Surg, 2023, 13(6): 3587-3601. |
| [17] |
张倩, 王大为, 隋时, 等. 深度学习计算机辅助诊断系统检测胸部DR肋骨骨折的验证性研究[J]. 中国临床医学影像杂志, 2022, 33(6): 430-434. ZHANG Q, WANG D W, SUI S, et al. A confirmatory study of deep learning based computer-aided diagnosis system for detecting chest DR rib fractures[J]. J China Clin Med Imaging, 2022, 33(6): 430-434. |
| [18] |
TANZI L, VEZZETTI E, MORENO R, et al. Hierarchical fracture classification of proximal femur X-Ray images using a multistage Deep Learning approach[J]. Eur J Radiol, 2020, 133: 109373. |
| [19] |
葛淳棉, 詹敏敏, 邓慧琪, 等. 强制分布评价制度对员工创新绩效的影响研究[J]. 中国人力资源开发, 2022, 39(3): 6-22. GE C M, ZHAN M M, DENG H Q, et al. Research on the impact of forced distribution rating system on innovation performance of employees[J]. Hum Resour Dev China, 2022, 39(3): 6-22. |
| [20] |
REDMON J, FARHADI A. YOLO9000: better, faster, stronger[EB/OL]. 2016: arXiv: 1612.08242. https://arxiv.org/abs/1612.08242.
|
| [21] |
HUANG J, RATHOD V, SUN C, et al. Speed/accuracy trade-offs for modern convolutional object detectors[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). July 21-26, 2017, Honolulu, HI, USA. IEEE, 2017: 3296-3297. DOI: 10.1109/CVPR.2017.351.
|
| [22] |
TAN M X, LE Q V. Efficient NetV2: Smaller Models and Faster Training[EB/OL]. 2021: arXiv: 2014, 00298. https://arxiv.org/abs/2014, 00298.
|