




2. 400038 重庆,陆军军医大学(第三军医大学):生物医学工程与影像医学系数字医学教研室;
3. 561000 贵州 安顺,安顺人民医院妇科;
4. 400038 重庆,陆军军医大学(第三军医大学):第一附属医院妇产科
2. Department of Engineering and Imaging Medicine, Cdlege of Biomedical Engineering and Imaging Medicine, Army Medical University (Third Military Medical University), Chongqing, 400038;
3. Department of Gynecology, Anshun People's Hospital, Anshun, Guizhou Province, 561000;
4. Department of Obstetrics and Gynecology, First Affiliated Hospital, Army Medical University (Third Military Medical University), Chongqing, 400038, China
盆腔脏器脱垂(pelvic organ prolapse, POP)是一类因盆底支持组织薄弱而造成盆腔器官下降移位及功能异常的疾病,常合并压力性尿失禁和大便失禁。年轻女性POP发病率为10%,而绝经后妇女可达到50%,对妇女的健康和生活质量造成严重影响[1]。
在早期诊疗中,放射科医师常根据肛提肌裂孔大小的三维建模和定量测量来评价POP,其依据为肛提肌损伤的范围与POP的严重程度呈正相关关系[2]。因此,肛提肌的分割、形态识别和三维建模对POP诊断和手术规划具有重要的临床意义。其中,肛提肌的分割是基础但非常关键的一步,其结果的好坏直接影响到后续识别和三维建模的精度。临床上,主要借助商业软件辅助对盆底核磁共振图像(MRI)中的肛提肌进行人工勾画[3],但肛提肌的解剖形态及其毗邻关系比较复杂,这种在MRI图像断层上进行手动勾画的方式易受到医生主观经验影响,分割结果误差大,分割步骤繁琐并且耗时较长。因此,临床上亟须对肛提肌的智能辅助分割进行研究,构建自动分割模型,以期提高分割效率和精准度,减低医师的工作强度。
近年来,随着深度学习技术的飞速发展,许多基于卷积神经网络的自动分割模型被提出并广泛应用于医学MRI图像的分割。如GUO等[4]提出了一种结合深度特征学习和稀疏补丁匹配的可变形MRI图像前列腺分割方法;LAVDAS等[5]提出了肿瘤学在MRI图像中实现全身病变检测的三维卷积神经网络全自动分割算法;BELLO等[6]基于深度学习,在302例患者的心脏三维MRI影像数据上首次实现了对四维影像数据的全自动处理。在盆底肌肉的分割方面,深度学习已应用于盆底超声中肛提肌裂孔的分割,并取得了较好的分割结果[7-9]。然而,由于MRI图像下盆底肌肉细小,解剖形态和空间毗邻关系复杂,MRI图像下基于深度学习的肛提肌自动分割研究还非常少,而且难度较大。
本研究在前期盆底断层解剖学的基础上[10-12],构建了盆底MRI图像的肛提肌图像标注数据库。为实现盆底MRI图像下肛提肌的自动智能分割,以DenseUnet为主干,融入上下文提取模块,提出了一个用于盆底MRI图像中肛提肌自动分割的网络模型。
1 资料与方法 1.1 研究对象本实验所使用的数据集为陆军军医大学提供的494张女性盆底MRI图像。这些影像图来自19例女性盆底MRI影像,其中含1例盆腔脏器脱垂1度(POP1)患者,3例盆腔脏器脱垂2度(POP2)患者和15例正常女性盆底MRI影像。使用14例正常女性盆底MRI影像、1例POP1患者和2例POP2患者作为训练集,1例正常女性盆底MRI影像和1例POP2患者作为测试集。将每例出现肛提肌的二维切片图像提取出来,得到446张训练图像、48张测试图像。训练图像和测试图像均由原始数据另存为DICOM格式,使用Python的第三方库Pydicom提取,并裁剪到512×290(ROI提取)得到。训练图像掩模由专业医师标注图像经过上述处理最后使用最大类间方差法[13]得到。最大类间方差法是一种利用图像灰度信息,选取最佳阈值,将图像分割为前景和背景的方法,它不受图像亮度和对比度的影响,能有效二值化分割图像。随机选取的2张女性盆底MRI影像及其肛提肌掩膜如图 1所示。

|
| 图 1 女性盆底MRI影像及其肛提肌掩膜 |
1.2 方法 1.2.1 网络模型
为了提高图像分割精度,克服Unet较少利用上下文信息及不同感受野下的全局信息的缺点,我们设计了以DenseUnet为主干,融入上下文提取模块的网络模型。
在这一节中,我们将介绍此研究中使用的DenseUnet框架。如图 2所示,网络主要由编码器模块、上下文提取模块和解码器模块3部分组成,在1.2.2~1.2.4小节中将对这3个模块进行详细介绍。

|
| 图 2 DenseUnet模型框架 |
1.2.2 编码器模块
编码器模块由4个密集块和4个最大池化层组成。密集块的结构如图 3所示,卷积一层和卷积二层的卷积核大小为3且卷积核个数相同,4个密集块中卷积一层和卷积二层的卷积核个数从上到下分别是64、128、256、512。批归一化层作用在通道轴上,后接线性整流(rectified linear unit, ReLU)激活函数。卷积二层的输出经过丢弃层最后和卷积一层的输出在通道轴上拼接在一起。4个最大池化层的卷积核大小为2,步长为2,每个最大池化层将图像大小变为原来的一半,但不改变图像通道数。

|
| 图 3 编码器与解码器中密集块框架 |
编码器模块将图像下采样,获得更抽象、更高级的图像特征。同时,密集块的密集连接提高了对特征的复用能力,减少模型在训练中的图像信息损失。
1.2.3 上下文提取模块上下文提取模块由密集空洞卷积(dense atrous convolution,DAC)模块和残差多核池化(residual multi-kernel pooling,RMP)模块组成。这两个模块由GU等[14]首次提出,为更好地提取所使用数据集的特征,本研究对这两个模块进行了改进。
密集空洞卷积模块采用了与Inception基本模块[15]类似的并行多分支结构,增加了网络宽度,同时在各分支上使用了空洞卷积[16],具体框架如图 4所示。空洞卷积有如下两个优点:一是在不改变卷积核参数量的同时,扩大了卷积的感受野,有助于从不同尺度提取图像特征;二是避免了池化层扩大感受野时缩小图像尺寸的副作用。从图 4可以看到,密集空洞卷积模块各个分支上使用1×1或3×3的卷积,卷积核个数均为512,膨胀率为1或3或5,各分支从左到右的感受野分别为3、7、9、19,使网络可从不同尺度上提取特征。考虑到残差连接中的加法操作可能会妨碍网络中信息的流动[17],因此,在我们所设计的密集空洞卷积模块中,各个分支的输出最后在通道轴上拼接在一起,进行特征融合并获取上下文信息,这与原文献[14]中采用残差连接将输入和各分支输出直接相加不同。此外,由于本研究采用的训练数据集为446张图像,因此,密集空洞卷积模块上各分支卷积核个数取为512,若采用原文献[14]中1024的卷积核个数很容易导致过拟合,进而造成分割精度的下降和计算资源的浪费。

|
| 图 4 上下文提取模块中密集空洞卷积模块框架 |
残差多核池化模块如图 5所示。在该模块中,受PSPNet中金字塔池化模块[18]的启发,我们采用了4个卷积核大小分别为2×2、3×3、5×5、6×6的最大池化,步长皆为1,为减少参数后面都接了1个1×1的卷积核,最后将输入和各分支输出在通道轴上拼接在一起。这种不同大小的池化操作允许网络在不同尺度上提取图像特征。同时,考虑到肛提肌位置相对不变性,我们将最大池化层的卷积核步长都设为1,并采用零填充使图像大小保持不变,这样有助于网络分割每例最开始几层的小肛提肌。这与原文献[14]将4个最大池化步长设为2、3、5、6并上采样回原始图像大小的操作不同。

|
| 图 5 上下文提取模块中残差多核池化模块框架 |
上下文提取模块的输入输出图像大小保持不变,意味着可以较为容易地加到其他网络框架中去,而且它能够提取上下文语义信息,产生更高阶的特征图,从而提高网络模型的准确性。
1.2.4 解码器模块解码器模块由4个密集块和4个上采样层组成。上采样层的作用与编码器中最大池化层的作用刚好相反,它将图像大小变为原来的两倍。每个上采样层中在上采样操作后都接了一层卷积层,卷积核大小均为2,卷积核个数从下到上为512、256、128、64。上采样层的输出与解码器模块之间使用跳跃连接(skip connection)。密集块的结构与图 3相同,密集块中卷积一层和卷积二层的滤波器个数从下到上分别是512、256、128、64。最后一个密集块的输出还通过了两层卷积层才得到了最后的输出,这与图 2稍微有所不同,详细的网络结构见1.2.6节。
解码器模块将图像上采样恢复到输入图像分辨率,但图像上采样实际上并不能完全还原图像信息,所以通过跳跃连接将浅层的纹理特征与深层的语义特征进行融合,从而恢复一些图像的边界信息,进一步提高网络模型的分割精度。
1.2.5 损失函数在本研究中,我们使用Dice损失函数作为网络的损失函数。
Dice相似性系数(DSC)常用于计算两个集合的相似度,其计算公式为:
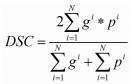
其中,g为真值掩膜二值图,p为预测掩膜二值图,gi为真值掩膜二值图上第i个像素实际属于的类别,pi为预测掩膜二值图上第i个像素实际属于的类别,N为像素点总个数。显然,相似性系数越接近于1,表明分割结果越好;反之,相似性系数越接近于0,表明分割结果越差。
Dice损失函数的计算公式如下:
1.2.6 网络结构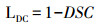
详细的网络结构由表 1所示,输入256×256×1大小的图像,网络同样输出256×256×1大小的图像,保持输入输出图像大小不变。
| 层 | 输入 | 卷积核 | 填充 | 步长 | 输出 |
| 密集块(一) | 256×256×1 | 256×256×128 | |||
| 最大池化(一) | 256×256×128 | 2×2×1 | 2 | 128×128×128 | |
| 密集块(二) | 128×128×128 | 128×128×256 | |||
| 最大池化(二) | 128×128×256 | 2×2×1 | 2 | 64×64×256 | |
| 密集块(三) | 64×64×256 | 64×64×512 | |||
| 最大池化(三) | 64×64×512 | 2×2×1 | 2 | 32×32×512 | |
| 密集块(四) | 32×32×512 | 32×32×1 024 | |||
| 丢弃 | 32×32×1 024 | 32×32×1 024 | |||
| 最大池化(四) | 32×32×1 024 | 2×2×1 | 2 | 16×16×1 024 | |
| 密集空洞卷积 | 16×16×1 024 | 16×16×2 048 | |||
| 残差多核池化 | 16×16×2 048 | 16×16×2 052 | |||
| 上采样(一) | 16×16×2 052 | 2×2×1 | 2 | 32×32×2 052 | |
| 卷积(一) | 32×32×2 052 | 2×2×2 052 | 1 | 1 | 32×32×512 |
| 拼接(一) | 32×32×512 | 32×32×1 536 | |||
| 密集块(五) | 32×32×1 536 | 32×32×1 024 | |||
| 上采样(二) | 32×32×1 024 | 2×2×1 | 2 | 64×64×1 024 | |
| 卷积(二) | 64×64×1 024 | 2×2×1024 | 1 | 1 | 64×64×256 |
| 拼接(二) | 64×64×256 | 64×64×768 | |||
| 密集块(六) | 64×64×768 | 64×64×512 | |||
| 上采样(三) | 64×64×512 | 2×2×1 | 2 | 128×128×512 | |
| 卷积(三) | 128×128×512 | 2×2×512 | 1 | 1 | 128×128×128 |
| 拼接(三) | 128×128×128 | 128×128×384 | |||
| 密集块(七) | 128×128×384 | 128×128×256 | |||
| 上采样(四) | 128×128×256 | 2×2×1 | 2 | 256×256×256 | |
| 卷积(四) | 256×256×256 | 2×2×256 | 1 | 1 | 256×256×64 |
| 拼接(四) | 256×256×64 | 256×256×192 | |||
| 密集块(八) | 256×256×192 | 256×256×128 | |||
| 卷积(五) | 256×256×128 | 3×3×128 | 1 | 1 | 256×256×2 |
| 卷积(六) | 256×256×2 | 1×1×2 | 1 | 1 | 256×256×1 |
2 结果 2.1 实现细节和参数设置
DenseUnet网络代码使用以Tensorflow作为后端的Keras框架实现。读入的训练图像首先经过数据增强(随机旋转、随机缩放、水平翻转等),然后改变图像大小到256×256,最后进行归一化处理。图像掩模执行与训练图像相同的操作。测试图像读入后先进行归一化处理,然后同样改变图像大小到256×256。
滤波器的权重初始化采用恺明正态分布[19]。随机种子设为10,在训练期间,权重通过学习率为0.000 3的Adam优化器更新,最后一层的激活函数使用Sigmoid函数,密集块中的丢弃层比率均设为0,表 1中丢弃层比率设为0.5。训练图像生成器批量大小为2,训练轮次为60次,批量轮次为223,选择损失最低的模型保存。
训练完成后,首先使用训练好的模型在测试集上进行预测,得到预测概率图。然后采用最大类间方差法找到合适的阈值二值化预测概率图,再将得到的二值图放大到512×290。最后与真值掩模二值图进行比较,计算出相似性系数(DSC)、豪斯多夫距离(HD)、平均对称面距离(ASSD)三个评价指标。
2.2 计算时间实验系统为Ubuntu 18.04.4 LTS服务器,配置为1块Intel Core i9-9820X CPU(3.30GHz)、2块NVIDIA GeForce RTX 2080Ti GPU。预测概率图后处理的操作使用MATLAB R2015a完成。训练DenseUnet花费25.2 min,预测48张测试图片用时1s。
2.3 分割精度采用本研究提出的DenseUnet模型在测试集上进行测试,并比较其与Unet、ResUnet、Unet++ 3种模型对肛提肌的分割精度。从评价标准的箱线图和分割结果的定量化评价指标可以看出,与其他3个模型相比,所提的DenseUnet模型拥有更高的相似性系数平均值和更低的豪斯多夫距离平均值、平均对称面距离平均值。同时,DenseUnet模型的箱线图比较短,说明该模型具有较好的一致性。详见图 6和表 2。

|
| 第1行到第3行的评价指标分别是相似性系数、豪斯多夫距离和平均对称面距离,第1列到第4列的网络模型分别是DenseUnet(蓝色)、Unet(红色)、ResUnet(绿色)、Unet++(紫色) 图 6 各模型在不同评价指标上的箱线图 |
| 模型 | 相似性系数(%) | 豪斯多夫距离/mm | 平均对称面距离/mm |
| DenseUnet | 77.1±9.4 | 16.0±7.4 | 0.9±0.8 |
| Unet | 75.3±8.6 | 22.7±12.6 | 1.3±0.8 |
| ResUnet | 74.7±9.9 | 24.0±20.6 | 1.3±1.1 |
| Unet++ | 71.6±11.9 | 26.5±17.4 | 1.7±1.3 |
为了更加直观地比较DenseUnet模型与其他的模型的分割效果,我们对4个模型在测试集中选取的3张图像的分割结果进行可视化比较。所提的DenseUnet模型在复杂的盆底MRI图像中能更准确地找到肛提肌的位置,并对不同图像具有较强的分割结果,详见图 7。对应的定量化评价指标见表 3。

|
| 从左到右:原始盆底图像、基于Unet++、ResUnet、Unet、DenseUnet模型获得的结果和真值掩膜 图 7 各模型的肛提肌分割结果的可视化比较 |
| 模型_第几行图片 | 相似性系数(%) | 豪斯多夫距离/mm | 平均对称面距离/mm |
| DenseUnet_1 | 88.4 | 10.0 | 0.3 |
| Unet_1 | 88.2 | 7.6 | 0.3 |
| ResUnet_1 | 85.5 | 8.6 | 0.4 |
| Unet++_1 | 86.4 | 9.9 | 0.4 |
| DenseUnet_2 | 88.3 | 7.8 | 0.2 |
| Unet_2 | 87.2 | 10.6 | 0.3 |
| ResUnet_2 | 83.7 | 13.9 | 0.5 |
| Unet++_2 | 85.9 | 17.5 | 0.5 |
| DenseUnet_3 | 71.7 | 30.1 | 1.8 |
| Unet_3 | 65.4 | 30.5 | 2.8 |
| ResUnet_3 | 62.0 | 30.1 | 3.5 |
| Unet++_3 | 61.8 | 30.5 | 3.4 |
| 评价指标分别是相似性系数、豪斯多夫距离和平均对称面距离。数据格式:平均值 | |||
最后,我们讨论所提的DenseUnet模型对测试集图像的分割效果。图 8展示了DenseUnet模型自动分割和手工分割的结果对比。虽然所提模型对个别图像分割精度不高,但模型对整个测试集总体保持较好的分割效果,在测试集的正常女性盆底MRI影像上相似性系数平均值达到81.2%,在其POP2患者上相似性系数平均值达到74.5%。

|
| 第1列是相似性系数值最低的两张图像,第2列是计算相似性系数值居中的两张图像,第3列是相似性系数值最高的两张图像。绿色线条为模型自动分割,红色线条为手工分割 图 8 Dense Unet模型分割与手工分割的结果对比 |
3 讨论
通过对比Unet,ResUnet和Unet++,所构建的DenseUnet模型的优点主要在于:模型中上下文提取模块的使用扩大了感受野,使其在提取图像特征的过程中能够更多地结合图像的上下文信息,在分割肛提肌时考虑毗邻肌肉的信息,这些辅助信息有利于在肛提肌损伤和移位的情况下,更准确地分割出肛提肌,这在图 7的第1行、第3行图像中皆有体现。缺点是,扩大了感受野之后,模型对小目标肌肉的注意力下降,而在每个病例出现肛提肌的最初的几张MRI图像中,肛提肌是比较小的,这就造成了模型对这些图像的分割精度低于其他3个模型。Unet模型优点是对测试集中正常例的分割精度较高,且在测试集上相似性系数值的标准差是最低的,说明Unet模型分割精度比较稳定。缺点是对POP2病例的分割精度较低,出现了一些点状的误分割,原因在于没有充分考虑到图像的上下文信息。ResUnet和Unet++分别使用了残差连接和密集连接,优点是防止了训练中梯度消失的问题,缺点是模型似乎训练得过好,发生了过拟合,导致在测试集上表现不佳。另外从训练时间的角度,Unet训练时间最短(参数量越少训练时间越短),其次是所提的DenseUnet,最后是Unet++和ResUnet。对于预测时间,所有模型皆在1s内完成48张图像预测。
在实验过程中,我们观察到:①如果模型对测试集中正常例分割精度较高,那么它对测试集中POP2的分割精度就会相对降低,反之亦然。可能的原因之一是,数据集中正常例与POP2例的MRI图像质量有一定差异,如成像设备参数设置不同,运动伪影等。图像质量不同会造成模型训练时学习到的分布与测试的图像分布不一致,从而导致测试集中分割精度的下降。另外,模型训练时有一定的随机性,有时对正常例的分布学得较好,有时对POP2例的分布学得较好。这是由实验数据中正常例和POP2例数据不平衡导致的。最佳的解决方法是收集更多的数据,尽量使正常例与POP病例数据平衡。②POP2例的分割精度低于正常例的分割精度,这主要是由于训练集中POP2例太少造成的,而且,POP2导致盆底肌肉损伤和移位也会影响分割精度。③所有模型在每个病例出现肛提肌的中间层的分割精度较高,在前层和后层的分割精度较低,这点与放射科医生一致,因为肛提肌越靠近会阴,它与会阴浅层以及肛门周围肌肉交叉融合越多,自动精准分割越困难。
本研究发现自动分割肛提肌的主要难点有3个,一是相比粗大的骨骼肌,肛提肌较小且薄;二是肛提肌边缘不明显,特别是肛提肌上部;三是肛提肌周围毗邻关系复杂,毗邻肛门外括约肌、尿道括约肌和闭孔内肌,这3个问题也是医疗图像分割的难点问题(小目标、弱边界、复杂背景)。除此之外,数据集少、专业医师分割标准各异、图像质量参差不齐也是严重阻碍医疗图像自动分割的问题。这些新的有价值的发现有助于国内对基于深度学习的肛提肌自动分割的进一步研究。
综上,与基于深度学习的超声下肛提肌裂孔的自动分割不同,本研究以DenseUnet为主干,融入上下文提取模块,提出了一个用于盆底MRI中肛提肌自动分割的网络模型。所提模型能够自动、有效地分割盆底MRI中的肛提肌,在1例正常女性盆底MRI影像和1例POP2女性盆底MRI影像上对肛提肌的分割精度优于Unet、ResUnet和Unet++ 3个经典的网络模型。研究的缺陷在于一是数据量比较少,二是没有使用三维的医学图像分割技术将层间的信息考虑进来,从而更有效地分割肛提肌。
| [1] |
中华医学会妇产科学分会绝经学组. 中国绝经管理与绝经激素治疗指南(2018)[J]. 协和医学杂志, 2018, 9: 512-525. Chinese Menopause Group, Obstetrics and Gynecology Branch of Chinese Medical Association. 2018 Chinese guideline on menopause management and menopause hormone therapy[J]. Med J PUMCH, 2018, 9: 512-525. |
| [2] |
ROSTAMINIA G, WHITE D, HEGDE A, et al. Levator ani deficiency and pelvic organ prolapse severity[J]. Obstet Gynecol, 2013, 121(5): 1017-1024. |
| [3] |
崔璨, 程悦, 沈文, 等. 女性盆腔器官脱垂病人肛提肌的MRI评价[J]. 国际医学放射学杂志, 2015, 38(2): 148-151. CUI C, CHENG Y, SHEN W, et al. Research progress of magnetic resonance imaging in evaluation of levator ani muscle for female patients with pelvic organ prolapse[J]. Int J Med Radiol, 2015, 38(2): 148-151. |
| [4] |
GUO Y, GAO Y, SHEN D. Deformable MR prostate segmentation via deep feature learning and sparse patch matching[J]. IEEE Trans Med Imaging, 2016, 35(4): 1077-1089. |
| [5] |
LAVDAS I, GLOCKER B, KAMNITSAS K, et al. Fully automatic, multiorgan segmentation in normal whole body magnetic resonance imaging (MRI), using classification forests (CFs), convolutional neural networks (CNNs), and a multi-atlas (MA) approach[J]. Med Phys, 2017, 44(10): 5210-5220. |
| [6] |
BELLO G A, DAWES T J W, DUAN J, et al. Deep learning cardiac motion analysis for human survival prediction[J]. Nat Mach Intell, 2019, 1: 95-104. |
| [7] |
YING T, LI Q, XU L, et al. Three-dimensional ultrasound appearance of pelvic floor in nulliparous women and pelvic organ prolapse women[J]. Int J Med Sci, 2012, 9(10): 894-900. |
| [8] |
LI X, HONG Y, KONG D, et al. Automatic segmentation of levator hiatus from ultrasound images using U-net with dense connections[J]. Phys Med Biol, 2019, 64(7): 075015. |
| [9] |
胡鹏辉, 王娜, 王毅, 等. 基于全卷积神经网络的肛提肌裂孔智能识别[J]. 深圳大学学报(理工版), 2018, 35(3): 316-323. HU P H, WANG N, WANG Y, et al. Automatic recognition of levator hiatus based on fully convolutional neural networks[J]. J Shenzhen Univ Sci Eng, 2018, 35(3): 316-323. |
| [10] |
WU Y, DABHOIWALA N F, HAGOORT J, et al. Architecture of structures in the urogenital triangle of young adult males; comparison with females[J]. J Anat, 2018, 233(4): 447-459. |
| [11] |
WU Y, DABHOIWALA N F, HAGOORT J, et al. Architectural differences in the anterior and middle compartments of the pelvic floor of young-adult and postmenopausal females[J]. J Anat, 2017, 230(5): 651-663. |
| [12] |
WU Y, DABHOIWALA N F, HAGOORT J, et al. 3D topography of the young adult anal sphincter complex reconstructed from undeformed serial anatomical sections[J]. PLoS ONE, 2015, 10(8): e0132226. |
| [13] |
OTSU N. A threshold selection method from gray-level histograms[J]. IEEE Trans Syst Man Cybern, 1979, 9(1): 62-66. |
| [14] |
GU Z W, CHENG J, FU H Z, et al. CE-net: context encoder network for 2D medical image segmentation[J]. IEEE Trans Med Imaging, 2019, 38(10): 2281-2292. |
| [15] |
SZEGEDY C, LIU W, JIA Y Q, et al. Going deeper with convolutions[C]//2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). June 7-12, 2015. Boston, MA, USA. IEEE, 2015. DOI: 10.1109/cvpr.2015.7298594.
|
| [16] |
YU F, KOLTUN V. Multi-scale context aggregation by dilated convolutions[EB/OL]. 2015: arXiv: 1511.07122[cs. CV]. https://arxiv.org/abs/1511.07122
|
| [17] |
HUANG G, LIU Z, VAN DER MAATEN L, et al. Densely connected convolutional networks[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). July 21-26, 2017. Honolulu, HI. IEEE, 2017. DOI: 10.1109/cvpr.2017.243.
|
| [18] |
ZHAO H S, SHI J P, QI X J, et al. Pyramid scene parsing network[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). July 21-26, 2017. Honolulu, HI. IEEE, 2017. DOI: 10.1109/cvpr.2017.660.
|
| [19] |
HE K M, ZHANG X Y, REN S Q, et al. Delving deep into rectifiers: surpassing human-level performance on ImageNet classification[C]//2015 IEEE International Conference on Computer Vision (ICCV). December 7-13, 2015. Santiago, Chile. IEEE, 2015. DOI: 10.1109/iccv.2015.123.
|